Sample a random distribution#
Parabola example#
Writing Monte-Carlo simulations solely in Python (only using standard modules) is possibly the slowest thing you can create in the universe, but it demonstrates the principle.
Let’s sample a parabola using only the Python standard library:
import random
def sample_parabola(xlim: tuple[float, float], size: int) -> list[float]:
output = []
ylim = 0, xlim[1] ** 2
while len(output) < size:
sample = random.uniform(*xlim) # random x-value
test = random.uniform(*ylim) # random y-value
if test < sample**2:
output.append(sample)
return output
Using timeit, one can test the runtime:
>>> import timeit
>>> timeit.timeit("sample_parabola((-2, 2), 10_000_000)", number=1)
9.827801200095564
Luckily, this can be sped up significantly using numpy methods:
import numpy as np
def sample_parabola(xlim: tuple[float, float], size: int) -> np.ndarray:
output = np.empty(size)
ylim = 0, xlim[1] ** 2
n_samples = 0
rng = np.random.default_rng()
while n_samples < size:
buffer = size - n_samples
# create multiple samples at once
sample = rng.uniform(*xlim, buffer) # random x-value
test = rng.uniform(*ylim, buffer) # random y-value
# test all samples at once
sample = np.ma.compressed(np.ma.masked_array(sample, test > sample**2))
# save "good" samples
output[n_samples : n_samples + sample.size] = sample
# repeat next turn with less samples
n_samples += sample.size
return output
This results in a runtime of
>>> import timeit
>>> timeit.timeit("sample_parabola((-2, 2), 10_000_000)", number=1)
0.331170630000997
A speedup of about 30!
This is all well and good if we know our distribution (here, a parabola). What if we want to do this for an arbitrary distribution?
The next section will go into that.
Sample arbitrary distribution#
Note
This method is provided by AplePy, see
sample_distribution().
import numpy as np
def sample_distribution(
distribution_edges: np.ndarray, distribution_values: np.ndarray, size: int
) -> np.ndarray:
output = np.empty(size)
n_samples = 0
rng = np.random.default_rng()
while n_samples < size:
buffer = size - n_samples
sample = rng.uniform(distribution_edges[0], distribution_edges[-1], buffer)
test = rng.uniform(0.0, np.max(distribution_values), buffer)
edges_index = np.digitize(sample, distribution_edges[1:-1])
sample = np.ma.compressed(
np.ma.masked_array(sample, test > distribution_values[edges_index])
)
output[n_samples : n_samples + sample.size] = sample
n_samples += sample.size
return output
The runtime of this is about 5 times slower than the numpy-example above. Sampling an arbitrary distribution comes at the cost of runtime!
Sample arbitrary analytic function#
Note
This method is provided by AplePy, see
sample_distribution_func().
What if we combine the first examples (sampling a parabola, i.e., an analytic function) and the previous example (sampling a completely arbitrary distribution)?
import numpy as np
from typing import Literal
from collections.abc import Callable
def sample_distribution_func(
f: Callable[[np.ndarray], np.ndarray],
xlim: tuple[float, float],
size: int,
ylim: Literal["auto"] | tuple[float, float] = "auto",
) -> np.ndarray:
"""
Sample a distribution described by `f`.
Parameters
----------
f : Callable
f must take one argument of type ``ndarray`` and return type
``ndarray``.
xlim : tuple[float, float]
"""
output = np.empty(size)
n_samples = 0
if ylim == "auto":
x = np.linspace(*xlim, 100)
y = f(x)
ylim = [np.amin(y), np.amax(y)]
rng = np.random.default_rng()
while n_samples < size:
buffer = size - n_samples
sample = rng.uniform(*xlim, buffer)
test = rng.uniform(*ylim, buffer)
sample = np.ma.compressed(np.ma.masked_array(sample, test > f(sample)))
output[n_samples : n_samples + sample.size] = sample
n_samples += sample.size
return output
The runtime of this is about the same as in Example 2, but we have more flexibility.
Sample discrete arbitrary distribution#
Note
This method is provided by AplePy, see
sample_distribution_discrete().
Sometimes it is not necessary to get a continuous distribution of values.
In this case, one can use numpy.random.choice().
import numpy as np
def sample_distribution_discrete(
values: np.ndarray, probabilities: np.ndarray, size: int
) -> np.ndarray:
probabilities_ = probabilities / np.sum(probabilities)
rng = np.random.default_rng()
return rng.choice(values, size, p=probabilities_)
Even though one is able to sample an arbitrary distribution with this, it is still about as fast as Example 2!
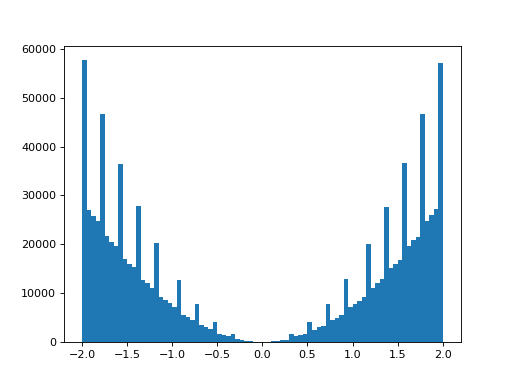
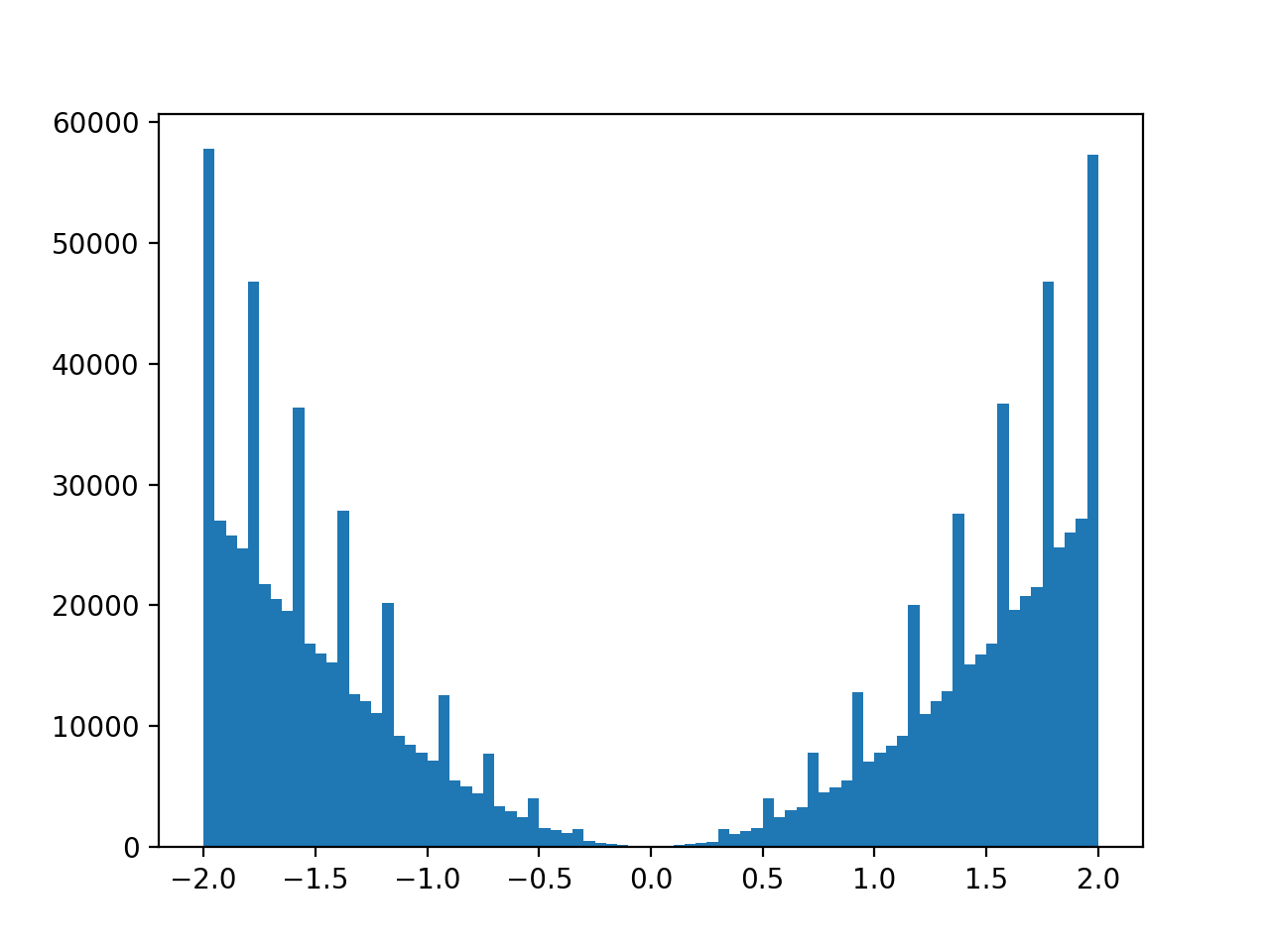
However, if one is not careful, this may result in Moiré patterns when histogramming the data into the wrong amount of bins, as illustrated by the following figure:
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}

Moiré pattern when sampling a distribution with 100 discrete x-values and histogramming it into 80 bins.#